AI Evals
Eval scores are garbage for many reasons, but let’s start with a very obvious one: scoring open ended things with accuracy and precision is virtually impossible, and pretending to do so is either naive or malicious (depending on your incentives).


I’m grumpy. First because I popped my knee on BJJ training. Second, because there’s a lot of misinformation and confusion about AI evals on the interwebs.
Well, can’t do anything about my knee while I’m on the computer.
Let’s do the second best thing.
What are AI Evals?
What I expected to happen, happened:
We’re hoping every software engineer working with AI becomes an AI Engineer. We’re also hoping some non-software engineers become AI Engineers too while we’re at it, why not.
But AI is not a field you can “wing it” — you need to learn this stuff. You don’t need to necessarily go to college for it, get an Ivy League PhD (tho that apparently helps?? I wouldn’t know) or work at one of the SOTA companies like OpenAI or Anthropic. But you DO need to learn it, as is made obvious by all the recent flopped trainings by top AI companies ministered by unqualified trainers.
So let’s start from the basics: what are AI evals?
AI evals are methods used for judging how good the AI is for a particular (set of) use case(s).
That’s it.
- When you see people saying “GPT 5.5 scored as high as Mythos on CyberGym’s security benchmark” that’s an AI eval measuring a model’s cybersecurity capabilities.
- When OpenAI says “SWE-bench Verified no longer measures frontier coding capabilities because it is increasingly contaminated, use SWE-bench Pro” they’re talking about model evaluations for writing code.
- When you read “Claude Code is not even on the top 40 in Terminal Bench 2.0” that’s a harness evaluation measuring anywhere between “software engineering” (we’ll get to the quotes in a sec) to math.
All these evals, and many others, are trying to answer the same question: “How good is the AI (model, model+harness, etc) for this particular set of use cases?”
I think there are many problems with the above framing of evals: lack of accuracy, undue extrapolations, unjustified precisions, etc.
But before we get to the bashing, let’s define and discuss AI Engineering.
What is AI Engineering?
I divide AI usage in 3 role buckets: Researchers, Engineers, and Operators:
- AI Researchers create AIs: Particularly new models. They go from defining model vocabulary and number of parameters to the last RLHF and finetuning circles. Slowly, it transitions to..
- AI Engineers build AI capabilities: Particularly in software applications. If your favorite web app now has a magic wand “use AI for [x]” (and you know that it does) it was added by an AI Engineer.
- AI Operators use AI: Particularly the AI built into applications. They use ChatGPT, Claude Code, Cursor, and all the other AI glue tools that exist to do their own jobs better.
AI Engineering is the work of building AI capabilities into applications. If you’re writing an application that’s calling a model or an AI harness, you’re doing AI Engineering.
But hold up: I said it means you’re doing AI Engineering.. but not necessarily a good one.
Knowing how to call an LLM from your application doesn’t automatically make it good AI Engineering any more than submitting a Qwen finetuning request on SiliconFlow makes it good AI Researching or vibe coding a CRUD Rails app on Claude Code passes for good AI Operations.
AI Engineering is its own discipline, with competencies to develop, pitfalls to avoid, best practices to follow and, like everything in AI, a world of things to uncover that can create an order of magnitude variability on the value of the work.
OK, now that we’ve established what AI Engineering is, let’s get back to evals and talk about the elephant in the room:
“How do those evals even come up with those scores, anyway?”
Eval scores are garbage
Look. I know it sounds harsh, but I told you I was grumpy today.
Eval scores are garbage for many reasons, but let’s start with a very obvious one: scoring open ended things with accuracy and precision is virtually impossible, and pretending to do so is either naive or malicious (depending on your incentives).
That doesn’t mean you can’t properly score something open ended given the right affordances to accuracy and precision.. but we rarely do it in AI evals (for whatever reason).
To start with, with any eval, you need to have some version of an Oracle: an entity entrusted with both “the truth” and a flawless evaluation of the truth when asked for it in eval scenarios.
If you say the Oracle for 2+2 math is a function that returns 4, you’re good to go, but 2+2=4 is not an open ended solution to a problem — it’s a well defined problem with a clear solution.
Now, I’ve been reading about oil. I know the current price of the barrel is ~$100, given the war. I also know the price of producing oil is on average ~$25 a barrel, but also ~$5 in the Middle East and ~$50 in Canada, but there are huge variables to this number including what externalities it takes into account, how it factors operation vs drilling costs, secondary extractions, etc. I’m not an Oracle, and this is an open ended problem.
In any case, given the info above, let’s see what GPT 5.5 says about how much it costs to produce a barrel of oil.
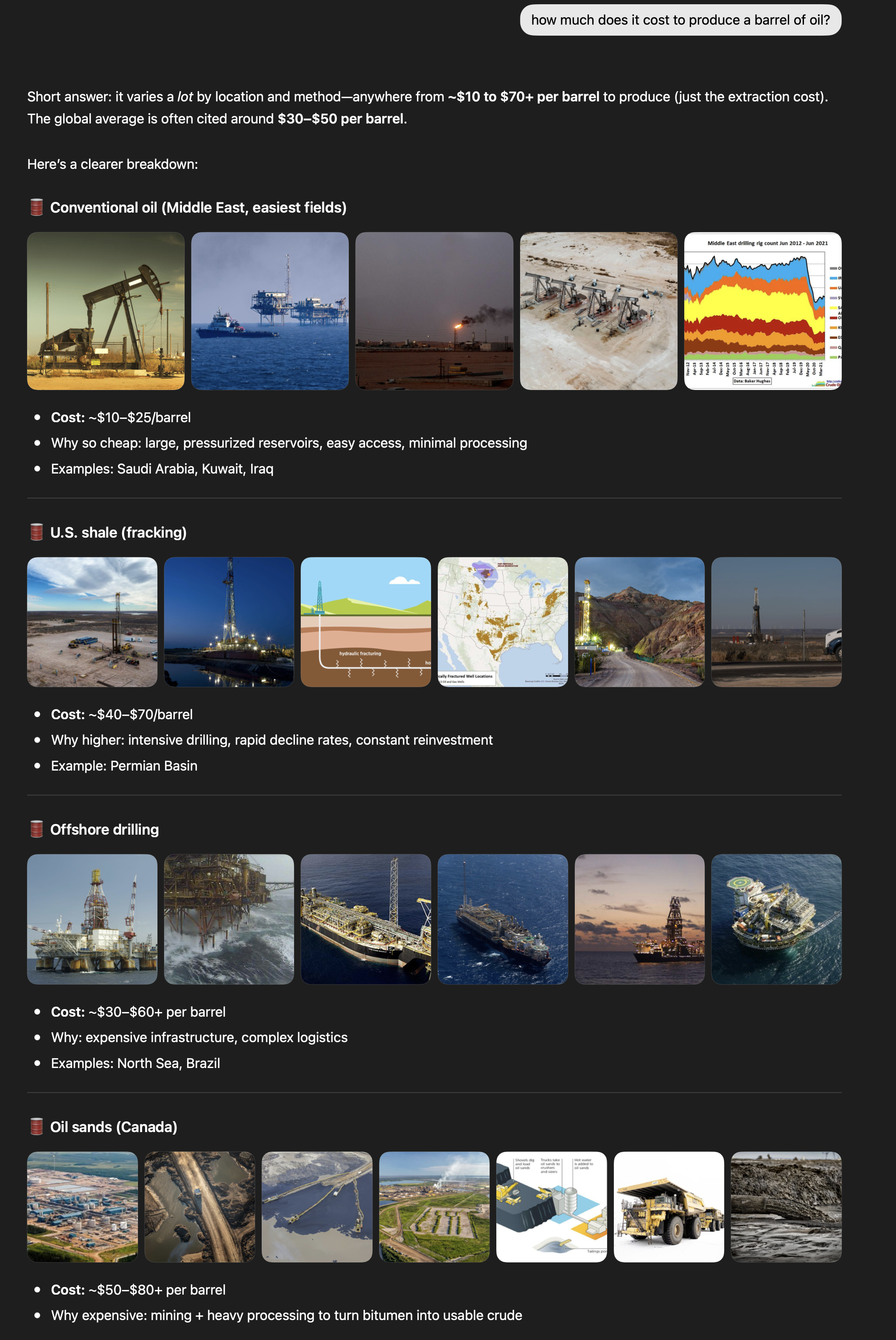
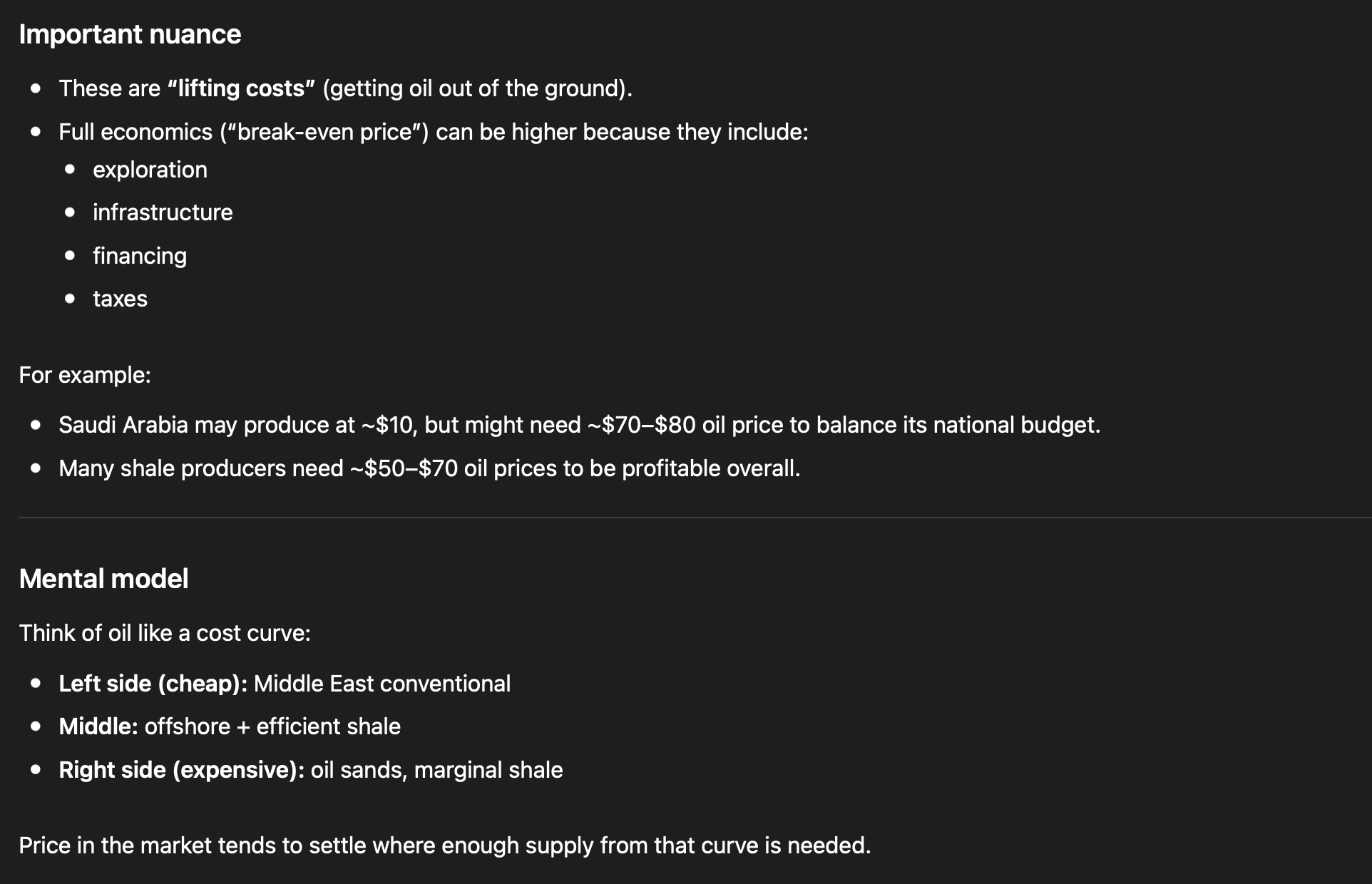
How good of an answer was this? Good? Not good? Great? Bad?
It did get the variation in regions correctly, and even quoted the same regions as I did! But its cost ranges are 2x higher than mine. What do we do with that??
Besides, maybe Vaclav Smil is wrong and GPT 5.5 is right about some things, and the costs should be represented as higher even without some of the externalities or taxes. Who knows.
Now let’s take this step further: out of a 0.00% to a 100.00%.. how would we rate this answer? 88.23%? 23.38%? How do we decide?
That, in short, is the essence of the issue of AI evals. The rest is commentary.
But the commentary is the fun part!
AI evals of open ended problems
When you read “GPT 5.5 / Opus 4.7 scored X% on [Eval]” — what does that mean to you? I mean, .. seriously, what should you do with that information?
Most people, rather understandably, will use it to judge “how good the AI is for [their] particular use case.” — that’s the point of evals, isn’t it? Is it a “software engineering” eval? Then it must mean [this] model is [this] good for my software engineering!!.. right??
WRONG!!
In fact, I almost think some of the coding evals are so bad as to be downright damaging to your judgement of AI’s efficacy. You’d know MORE by not seeing the score (and judging the AI however you’d have judged it otherwise, including vibes) than you do by seeing it.
So let’s explain why I think that is by drawing a parallel to my oil example and asking this very simple question, so relevant to AI evaluation today:
”How do you judge good software engineering?” — Go ahead, give it some hard thought. I’ll wait.
Right. Judging software engineering (and software engineers) is an art and not a science (the polite term we use for “it’s bullshit”) and has been pretty much since the advent of coding.
Note: It doesn’t mean there’s no difference between good coders and bad coders, good and bad software engineering, etc. Much to the contrary, there’s a huge difference! .. but how do you measure it, accurately and precisely?
At FANG companies in the early 2000s you’d measure it in technical interviews with questions like “how many pianos are there in the US?” Later, with “write the implementation of a double linked list on the whiteboard.” Other options were “bootstrap this app from scratch in 1 hour” or “code review and find all the bugs in this random open source PR.”
As I said, bulls.. art, not science.
Now, in tech companies’ (and mea culpa, eng leaders’) defense, we’ve been using ..art to evaluate software engineers since the dawn of time, so why not use it for AI too?
But while the level of delusion us tech leaders had with trying to foresee how well a software engineer would do in our company after 2 1-hour interviews was always a bit high (I wrote so many “he’s a star!!” on my scorecards), it was never AI-evaluation levels of delusional.
And again, it’s those pesky problems: system design, PR reviews, algorithms, etc — how do you score a 78.31% vs a 31.78%? And why?
So let’s talk about “software engineering” benchmarks and extrapolation.
AI evals of software engineering
Terminal Bench 2.0 has a bunch of problems in its “software engineering” category. Here’s Opus 4.7’s summary of the types of problems they encompass:
- Constrained reconstruction puzzles — reproduce a target output (an image, a binary's behavior, a compressed file's expansion, all legal chess moves, GPT-2 sampling, fib(isqrt(N))) under a brutal size or primitive-set limit (≤2KB gzipped, ≤2500 bytes, <100k regex pairs, logic gates only). Carlini's signature.
- Real-world build, modernize, and untangle — get gnarly legacy code to compile and run (POV-Ray 2.2, pMARS, OCaml GC, COBOL→Python), or fix what someone broke in git, pypi, or a Coq proof.
- Build the plumbing from scratch — implement the thing that normally Just Works: a metacircular Scheme evaluator, a MIPS interpreter, a headless terminal, gRPC KV store, tensor/pipeline parallelism, an async task runner that survives Ctrl-C.
Now, do these look like, at all, the types of things you spend your time doing at your day job? legal chess moves? POV-Ray 2.2? Scheme evaluators? Oh I knew your job was not THAT fun.
Well, but do these translate? Can my model implement a great Rails web-app controller if it can implement Doom for MIPS?
One of these two must be true (a conjunctive proposition):
- Problems extrapolate absurdly: Success in one problem means near certain success in many other problems. Therefore, we only need to test a small subset of problems to know how AI will behave.
- Problems don’t extrapolate absurdly: Success in one problem doesn’t mean near certain success in many other problems. Therefore, we need to test AI in a wide variety of problems to know how AI will behave.
Given all the types of 27 problems posed by Terminal Bench 2.0 for Software Engineering, which one do you think is true?
- Did we find the core 27 problems that magically translate to all of the software engineering domain (but not 26, 25, or 1.. after all, if there’s such absurd extrapolation, why not just pick 1 or a handful of problems?) .. or …
- We’re just trying to measure what’s easy even if it doesn’t matter for what we’re actually doing unless we’re writing Doom in MIPS?
God I’ll use bold again, so adding this sentence to cheat my AI editor.
Like the drunkard looking for his keys under the lamp because it’s easier to see even though that’s not where he lost them, we’re fooling ourselves by running evals under the light even tho that’s not where we lost our keys at all!
And worse, we’re saying we’ll find the keys under the lamp with 78.31% certainty, which is ahead of the other drunkard at 77.83%.
Fine, I’ve spent all this bold on the article and my knee still hurts..
..So, what can you do about it?
AI Evals .. the good parts
Some problems aren’t open ended. Some problems do extrapolate. Software engineering isn’t one of them, and neither is writing. But math can be, and so can parts of cybersecurity (such as finding exploits), among other use cases.
So here are my 3 tips:
1) Is this a well defined, rather than an open ended, problem? 2+2? well defined. US + Brazil? open ended. Eval more things like the former and fewer like the latter.
2) Does this extrapolate? If the solution to 2+2 holds, and I answer 3+3, 4+4, 5+5, does that mean I’m pretty confident on 6+6, 7+7.. or not?
3) Do I have an oracle? How do I know what good looks like? Is AI a good judge? Which and how? Are humans good judges? Are you sure?
On that last note, I’ll leave you with a warning that I thought I could remove from the article to make it shorter but I really can’t (so you’re stuck with me past the 2,000 words mark, sorry):
Warning) If you think AIs are bad at evals, you really haven’t tried humans yet. We are really terrible at this!
Seriously. Humans suck. Here’s one of my favorite examples from the AI Engineering O’Reilly book. Fuyu is the AI, the others are humans:

Seriously (again), in 2012 we had the Deep Learning revolution with AlexNet in image recognition reducing AI error rate to 15%, but less talked about is that in 2015 the AI competitors surpassed the 5% error rate of humans doing image recognition. 2015!
So, ideally, your answer to “do I have an oracle?” doesn’t involve humans evaling your solutions, because we suck at well-defined problems and can’t judge open-ended ones.
But there’s one last caveat to that:
Bonus) Comparative evaluation is often okay
While we may suck at saying A is 78.31% vs B is 31.78%, and A, B, and C may not be transitive at all, humans may do a good job of comparing which one between A and B is better for them.
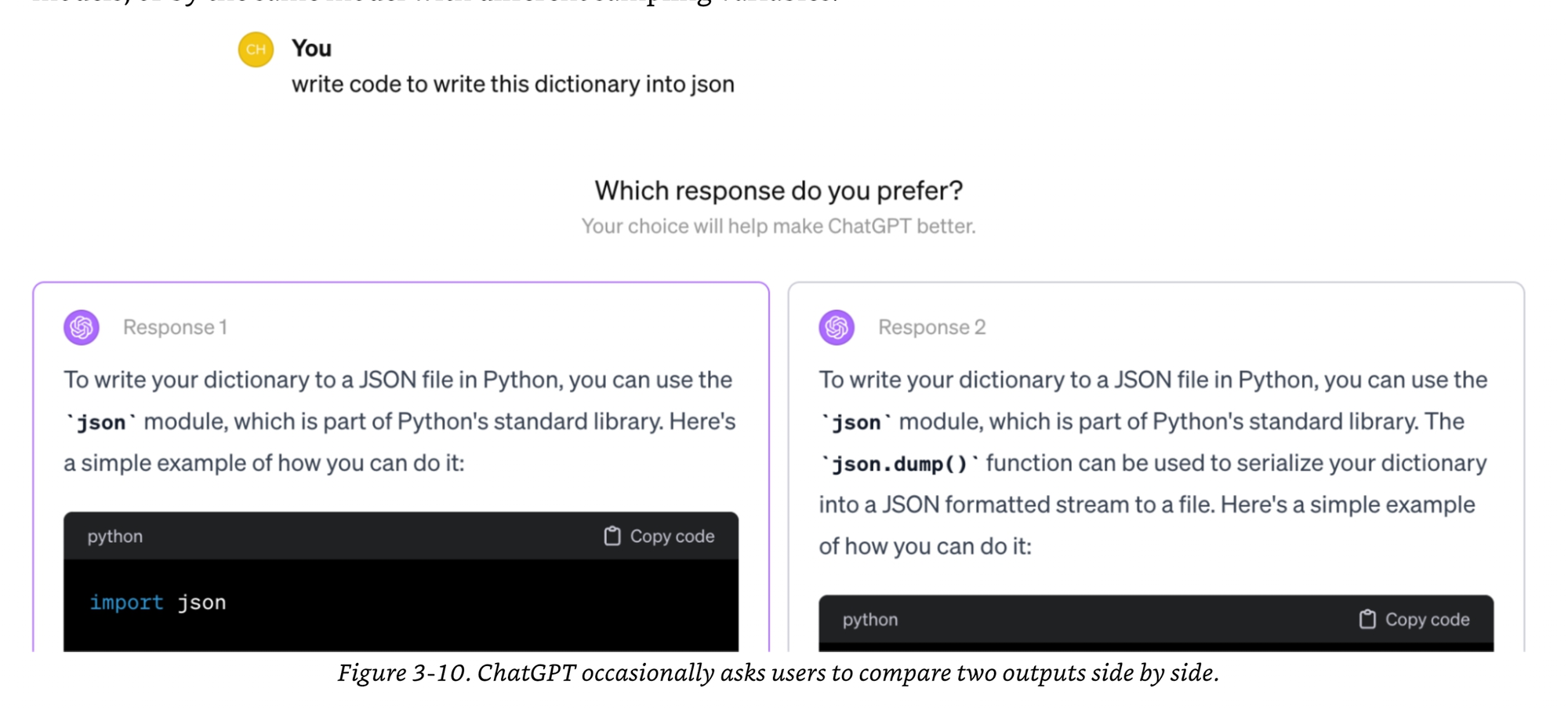
And this data can be valuable in figuring out which AI is better for your users: not which one is better at X, or extrapolating from X to Y, but literally what it’s measuring and only that: which, between the two options, your users prefer.
So that’s it for today. Now I have one fewer thing making me grumpy, .. and ah yes, hopefully the above helps you too!
Now, about that knee..